
Psychometrics tests vary in their length and complexity and can include either written or verbal questions. These tests require the person taking the test to answer questions based on their own knowledge or experience. They test aspects of a person like cognitive ability (e.g., reasoning or spatial ability), personality (e.g., emotional stability), vocational interests (e.g., how interested someone is in mathematics), educational attainment (e.g., how much schooling someone has completed), attitude towards work, or other kinds of attributes.

Well-developed psychometric tests are usually highly accurate and reliable for measuring aspects of a person’s character or abilities. Good psychometric tests are defined by a few desirable properties. These properties set psychometric tests apart by making human behaviour quantifiable and hence, more objective. Psychometrics is rooted in science, as we will understand when we explore its properties.
The desirable properties of psychometric measures are; Standardization, Reliability, Validity, and Norms.

Standardization: Standardization implies uniformity of procedures in administering and scoring the test. If the scores obtained by different persons are to be comparable, testing conditions must obviously be the same for all.
Generating of assessment items is based on review of literature, published theory, etc. Based on the context, type of items is generated: Multiple Choice, Forced Choice Technique, Situational Judgment Test / Questions (SJT / SJQ).
Administration of the test – standardisation involves “giving” the test the same way every time. Specific instructions, order of items, timing, etc. has to be the same as well.
Scoring of the test – test is “scored” the same way every time. A scoring manual is provided.

Reliability: It is the overall consistency of a measure. A measure is said to have a high reliability if it produces similar results under consistent conditions. There are various types of reliability that are checked.
- Inter-rater or Inter-observer reliability: Inter-rater reliability is the degree of agreement among raters. It is a score of how much homogeneity or consensus exists in the ratings given by various judges.
- Internal reliability: It refers to similarity or consistency between the results of one part of a measurement and those of other parts or the whole of that being observed. It answers important questions like, do the items measure a central “thing”? Will the items add up to a meaningful score?
- Test-retest reliability: It measures test consistency, i.e, the reliability of a test measured over time. In other words, give the same test twice to the same people at different times to see if the scores are the same.
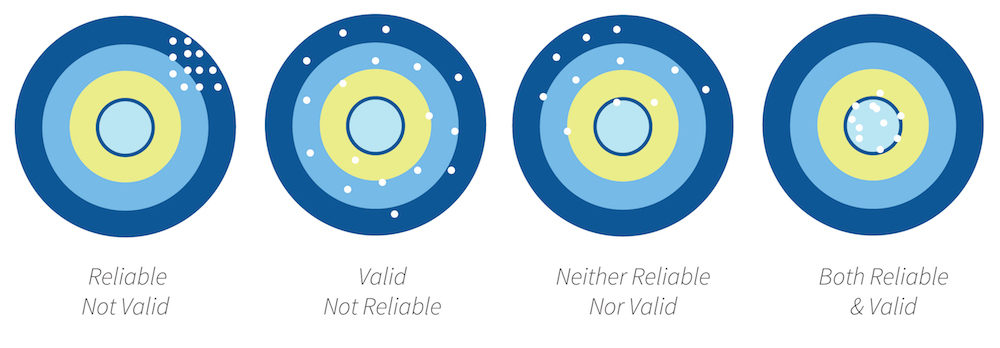
Validity: It is an assessment’s ability to measure what it claims to measure. Validity too is of different types, and a good test measures high on all the types of validity.
- Face Validity: Face Validity is concerned with whether a selection instrument appears to measure what it was designed to measure. Whilst face validity has no technical or statistical basis, it must not be overlooked if a test is to be accepted by the respondent.
- Content Validity: Content Validity (also known as logical validity) refers to the extent to which a measure represents all facets of the construct (e.g. personality, ability) being measured. For example, a depression scale may lack content validity if it only assesses the emotional dimension of depression but fails to take into account the behavioural dimension. When constructing any test or questionnaire, the items should be representative of the domain that is to be measured.
- Criterion-related Validity: Criterion or concrete validity is the extent to which a measure is related to an outcome. Criterion validity is often divided into concurrent and predictive validity based on the timing of measurement for the “predictor” and outcome.
- Concurrent — Concurrent validity is established when the scores from a new measurement procedure are directly related to the scores from a well-established measurement procedure for the same construct; that is, there is consistent relationship between the scores from the two measurement procedures
- Predictive — Assessing predictive validity involves establishing that the scores from a measurement procedure (e.g., a test or survey) make accurate predictions about the construct they represent . For example: A cognitive behavioral test score correlates with high job performance levels.
- Construct Validity: Construct Validity is the extent to which a test measures some established construct or trait. Such constructs might be mechanical, verbal or spatial ability, emotional stability or intelligence. Correlations with other scales will provide useful information on a test’s construct validity (eg., we would expect a scale of dominance to be more highly related to other measures of dominance than to traits of anxiety). Factor analysis is often used to investigate the construct validity of personality questionnaires.

Population Norms: In order to interpret a score from an individual or group, one must know what scores are typical for that population. A solid population norm can be developed if a large representative sample of the target population is taken. These norms help in,
- Finding a scoring distribution of the population
- To identify individual scores as “normal,” “high” & “low”
- To identify “cutoff scores” to put individual scores into importantly different populations and subpopulations
References
Criterion validity (concurrent and predictive validity) | Lærd Dissertation. (n.d.). Laerd Dissertation. Retrieved April 30, 2021, from https://dissertation.laerd.com/criterion-validity-concurrent-and-predictive-validity-p2.php
Validity of Psychometric Assessments. (n.d.). Retrieved April 30, 2021, from http://www.psychometric-assessment.com/validity-of-psychometric-assessments/
Comments 1
Good afternoon thanks for the information