
IRT a.k.a Item Response Theory is a buzzword in the domain of Psychometric Testing. There are hundreds of articles written in both – praise and criticism of this theory. Like all other theories, it is not perfect but very useful for certain purposes. So, what exactly is IRT?
IRT is a theory of modelling (representing) candidate`s response in a way that allows us to look at each response in isolation rather than looking at all the responses as a whole. This results into many significant advantages; e.g. one can present different questions to different test takers and can still compare them as if they have taken exactly the same test. The theory works on the assumption that a candidate`s response on a question is result of interaction between candidate`s ability and item`s difficulty irrespective of how others have performed on that test. If a candidate has greater ability than the difficulty of the item, she will have higher chances of getting it right. Sounds interesting? Lets see how this magic happens.
In classical test theory ( when there was no IRT) responses (on a test from a candidate) were modelled on the basic of total number of correct answer. If candidate A gives more number of correct answers than candidate B, then, candidate A is believed to have higher ability level than B. How much higher? This is determined by how others have performed on test (by calculating mean and standard deviation of the reference group). This kind of modelling makes the evaluative judgement (of Low, Medium or High) on test performance very much group dependent. The absolute ability of the candidate did not matter much in determining low, average or high. If a candidate with medium level of ability is compared with a group of all low ability candidate, she will be evaluated as ‘high’ whereas if the same candidate is compared with high ability (and therefore high scoring) candidate group, she will be evaluated as low. This necessitated that test developers be extra cautious not only in developing test-items that belong to the varying difficulty level but also select a ‘truly representative sample’ with entire ability spectrum ( candidates with varying ability levels covering entire targeted ability range ) in order to make good tests. If some questions are changed in future, the test needs to be re-administered on a ‘representative sample’ in order to provide a comparative judgement about a candidate on this new test.
Now enters IRT which offers to provides some relief from this tedious cycle of test development by looking at each item in a way that allows test developers to model them in relatively independent manner. It models (puts into formulae) the probability of getting a correct response for a given ability level of the candidate. The fundamental assumption is “ The candidate will have more than 50% chances of giving the correct response if the ability of the candidate (intended to be measured by that item) is equal to or greater than the difficulty of that item”. Sounds reasonable? Yes, it is :-). But this is the only thing which is simple about this theory, everything else is complex mathematical calculations that are simply too difficult to do on paper. Thankfully, we have powerful computers and readily available free algorithms (contributed by community of generous, self-centric and highly intelligent people) to do all the tedious work and get full advantage of IRT just by knowing 5th grade mathematics.
Going by IRT assumption above, here is how IRT scoring works. I have my responses on a set of items. I need to know my true ability level on the ability measured by those questions. Here is how the computer will proceed. First the computer needs to know the difficulty level of each and every item answered by me. There are multiple ways in IRT to estimate item-difficulty. I will leave that discussion for IRT books, for now, lets assume that the test developer has this information provided to the computer. Now the computer will assume that my ability is zero theta (which is the mid-point of a the ability continuum) and calculate the conditional probability of my answer pattern. Then it will increase my ability a little (lets say 0.01 theta) and will again calculate the probability of my answer pattern with this increased ability value. If the probability increases, it will again increase the estimate of my ability and will keep on increasing and recalculating till the increment in probability becomes zero or near zero. If the probability decreases, it means that my ability is lower than the average and the system will set a decreased estimate of my ability and recalculate probability (this time probability will increase), it will keep on decreasing the ability estimate and recalculating till the increase in probability becomes zero or near zero.
Unfortunately, there is no way to know the examinee’s actual ability. The best one can do is estimate it. However, this does not prevent us from conceptualising it. Fortunately, one can obtain a standard error of the estimated ability that provides some indication of the precision of the estimate.
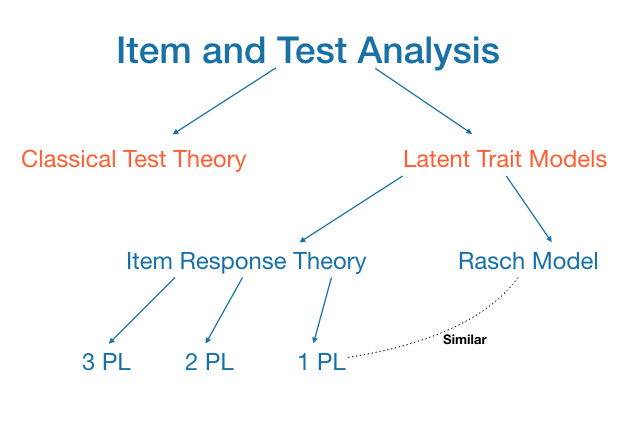
So, this is how IRT works. It is important to note here that the description above is very simplistic in nature and it talks only about item-difficulty and person-ability. In IRT terms this is close to Rash Model (many people believe that 1-parameter IRT model is equal to Rash Model but Rash Model fans do not agree with them). Other well known IRT models are 2-parameter model (which takes into account item-difficulty and item-discrimination, that is why it is called 2-parameter model) and 3-parameter model which accounts for guessing in addition to the previous two.
Please give your comments in this post and share it in your network if you think it is simple and lucid for non-technical users to provide an introduction to IRT.